Microsoft New Future of Work Report 2025.
Microsoft Research Tech Report MSR-TR-2025-58 (https://aka.ms/nfw2025), 2025.
I am currently a Senior Applied Scientist in Microsoft's IDEAS Research group. My research leverages one of the largest productivity data infrastructures in the world to build better AI agents. Specifically, I aim to (i) understand how AI tools are used in real productivity workflows, and (ii) turn those large-scale, data-driven insights into more capable agents & more intuitive human–AI interactions. Some recent work:

Led research on workflow inference from M365 signals and telemetry that powers agentic skills in Copilot Frontier Tuning. This enables customers to bring the "content, processes, conventions, terminology, and workflows that collectively define how their business runs" into an RL environment for lower-barrier tuning of agents. Build 2026 Keynote Microsoft 365 Blog Microsoft AI Blog
I received my Ph.D. in Computer Science from Georgia Tech, where I developed robust, efficient, and adaptable multimodal AI models. My work has been recognized by leading media outlets, multiple doctoral fellowships and grants, and best paper awards, and has led to academic publications and over a dozen patents that have influenced industry products (TechCrunch).
Before my Ph.D., I was a researcher at Adobe Research (India), working on multimodal content generation. I completed my undergraduate studies at IIT Kanpur, and during my doctoral studies I interned at JPMorgan AI Research, Microsoft Research, and Adobe Research.
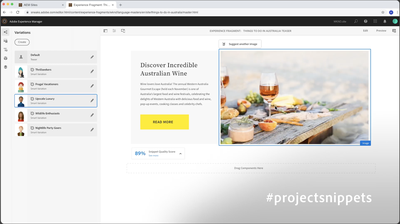
Led research on multimodal content synthesis, showcased as a Sneak at Adobe Summit and covered in TechCrunch. The innovation enables customers to present content to their audiences through AI-powered personalized image-text snippets. TechCrunch Adobe Research Blog Adobe Summit Sneak Video Patent Paper
Microsoft Research Tech Report MSR-TR-2025-58 (https://aka.ms/nfw2025), 2025.
In Proceedings of the ACM/AAAI Conference on Artificial Intelligence, Ethics, and Society (AIES 2025).
In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025).
In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024).
In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023).
In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023).